I get this question on a weekly basis (at least) – how many concurrent provisioning operations can vRA handle?
…and as soon as I say “2”, i get the [expected] follow up – how can I change that to something ridiculous?
Here’s how:
But first, let’s revisit the blanket statements above because they’re missing a lot of details. The REAL answer is “it depends”. Concurrency primarily depends on which Endpoint is configured, whether or not a proxy agent is used, and what the endpoint itself can handle. The vast majority of vRA customers have at least 1 vSphere Endpoint — which leverages a proxy agent — so I can confidently divulge the default concurrency of 2. Here’s a glimpse of those defaults…
- Proxy Agent-based (vSphere, XEN, Hyper-V) – 2 per agent
- DEM-based (all other supported endpoints) – no fixed limit (sort of, see below)
There are a few additional considerations:
- The number of concurrent workflows per DEM instance. That number is 15 (per DEM).
- While DEM-based endpoints have no theoretical limit, the DEM workflow concurrency of 15 (per DEM) does apply.
- Endpoint limits are at play (that is, the endpoints themselves). For example, vSphere 6 can handle 8 concurrent operations by default.
- Once a limit is reached, all additional requests are queued up until a slot opens up, regardless of where the limit occurs.
- While changing concurrency limits can provide a nice bump in productivity, be very aware of your environment’s needs and limitations to ensure you don’t overwhelm anything, this is especially true for storage.
- In many environments, the default concurrent provisioning settings will be sufficient…adjust only as needed.
With all that said, it’s fairly easy to hit these thresholds and come to the conclusion that the defaults are just not good enough. A given vRA environment is expected (designed) to scale and manage a greater number machines and users over time, especially as users get accustomed to self-service and the sysadmins “automate all the things!”. Hitting concurrency limits means larger queues, longer times for a machine to be available, and — potentially — running into timeout situations. And due to the fact that vRA provides concurrent access to several users across all tenants and allows any one user to request several machines at once, it won’t take long before you realize you need to bump things up.
Fortunately you can make some tweaks in your environment to [cautiously] help things along.
Here’s how (for real this time):
Manager Service (Global):
In this example, I’d like to increase the concurrent provisioning, also called a Resource-Intensive Work Item, for a vSphere Endpoint from 2 (the default) to 6. I’ve done my due diligence and decided 6 concurrent operations won’t overwhelm the endpoint or underlying infrastructure. You should also consider that the settings here are global per vRA instance and you must consider the lowest common threshold of all supported endpoints when changing the default. In this case, it’s vSphere.
1. Connect to your vRA IaaS (windows) server that hosts the Manager Service (if you’re running Manager Service is an HA pair, you’ll need to repeat this process for each node)
2. Browse to the vRA Manager Service installation directory – by default this is “C:\Program Files x86\VMware\vCAC\Server”
3. Locate the “ManagerService.exe.config” file, MAKE A BACKUP!, then open it with your editor of choice (i use Notpad++ because…why wouldn’t you??)
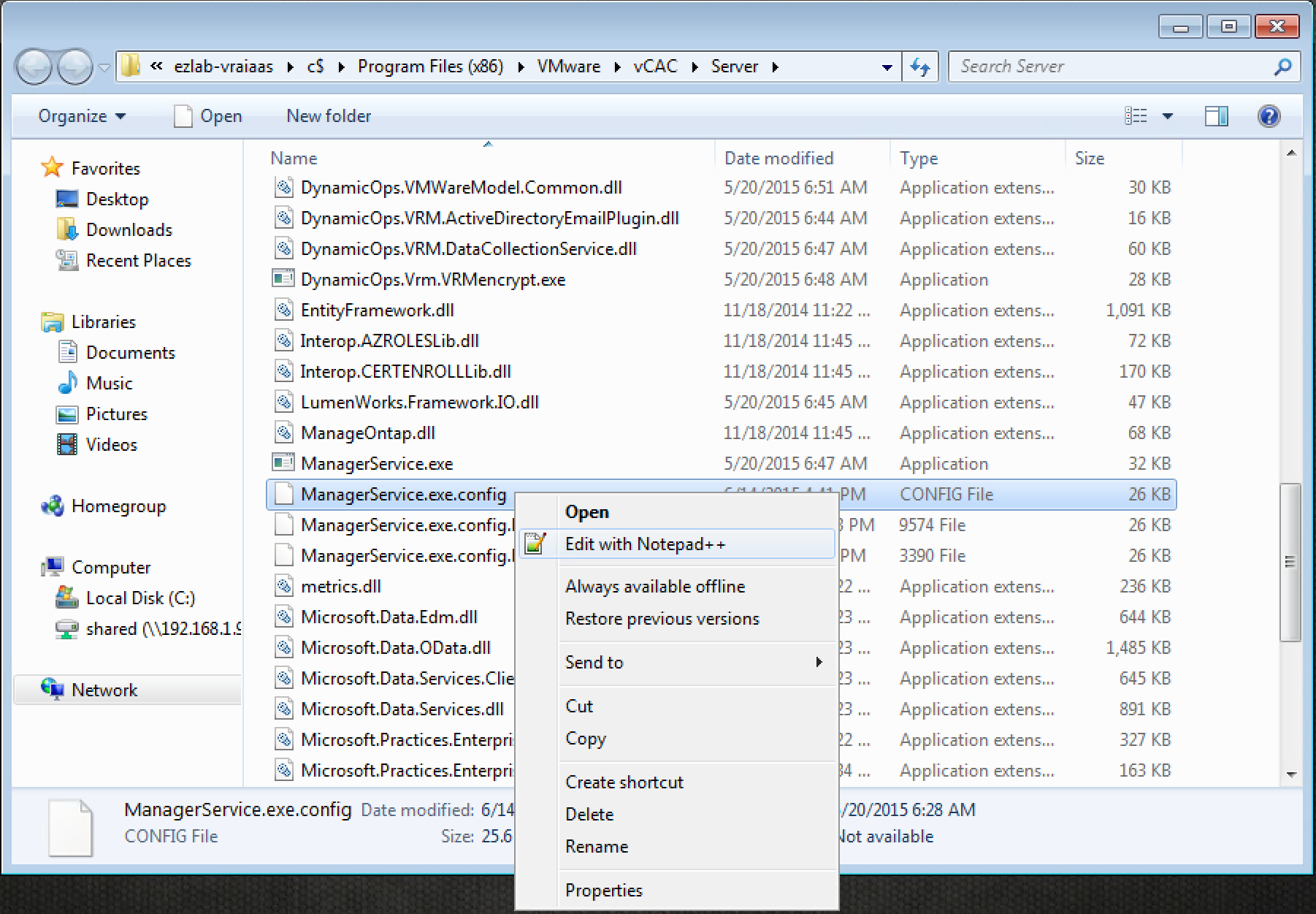
4. Locate the section called workflowTimeoutConfigurationSection (line 159)
5. Find “MaxOutstandingResourceIntensiveWorkItems”, change the default value of 2 to 6
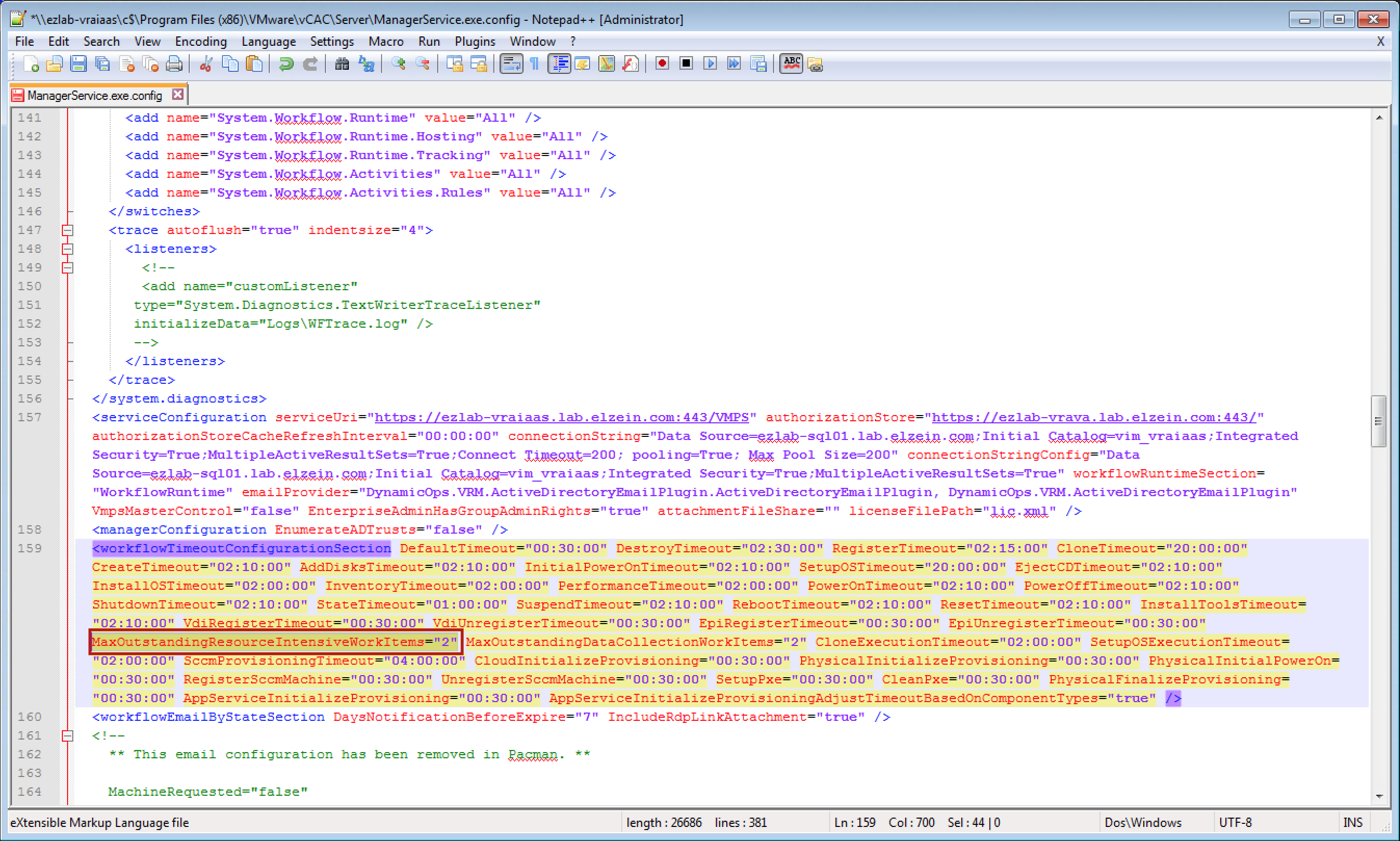
6. Save the changes and close the file
7. Restart the vCloud Automation Center service
8. Repeat on any Manager Service HA nodes
There are several other config parameters you can tweak in the “ManagerService.exe.config” file. Use sparingly depending on where your environment is hitting time or concurrency thresholds (if any). I’ve left these alone so far. From the vRA docs…
- CloneExecutionTimeout – Virtual provisioning execution timeout interval
- SetupOSExecutionTimeout – Virtual provisioning execution timeout interval
- CloneTimeout – Virtual provisioning clone delivery timeout interval
- SetupOSTimeout – Virtual provisioning setup OS delivery timeout interval
- CloudInitializeProvisioning – Cloud provisioning initialization timeout interval
- MaxOutstandingDataCollectionWorkItems – Concurrent data collection limit
- InventoryTimeout – Inventory data collection execution timeout interval
- PerformanceTimeout – Performance data collection execution timeout interval
- StateTimeout – State data collection execution timeout interval
Agent Config:
While the “MaxOutstandingResourceIntensiveWorkItems” parameter set concurrency globally, there is a per-agent setting that can also be tweaked to ensure you’re hitting the desired concurrency. The setting, “activeQueueSize”, is set to 10 by default. This means the agent can handle 10 concurrent operations (not just provisioning) to the associated endpoint before things start to queue up. I don’t have an exact answer for what this should be changed to in order to compliment the Manager Service setting, so I left it alone until I see a problem…
1. Connect to your vRA IaaS (windows) server that hosts the Agent(s) in question
2. Browse to the vRA Agent installation directory – by default this is “C:\Program Files x86\VMware\vCAC\Agents\%agent_name%”
3. Locate the “VRMAgent.exe.config” file, MAKE A BACKUP!, then open it with your editor of choice
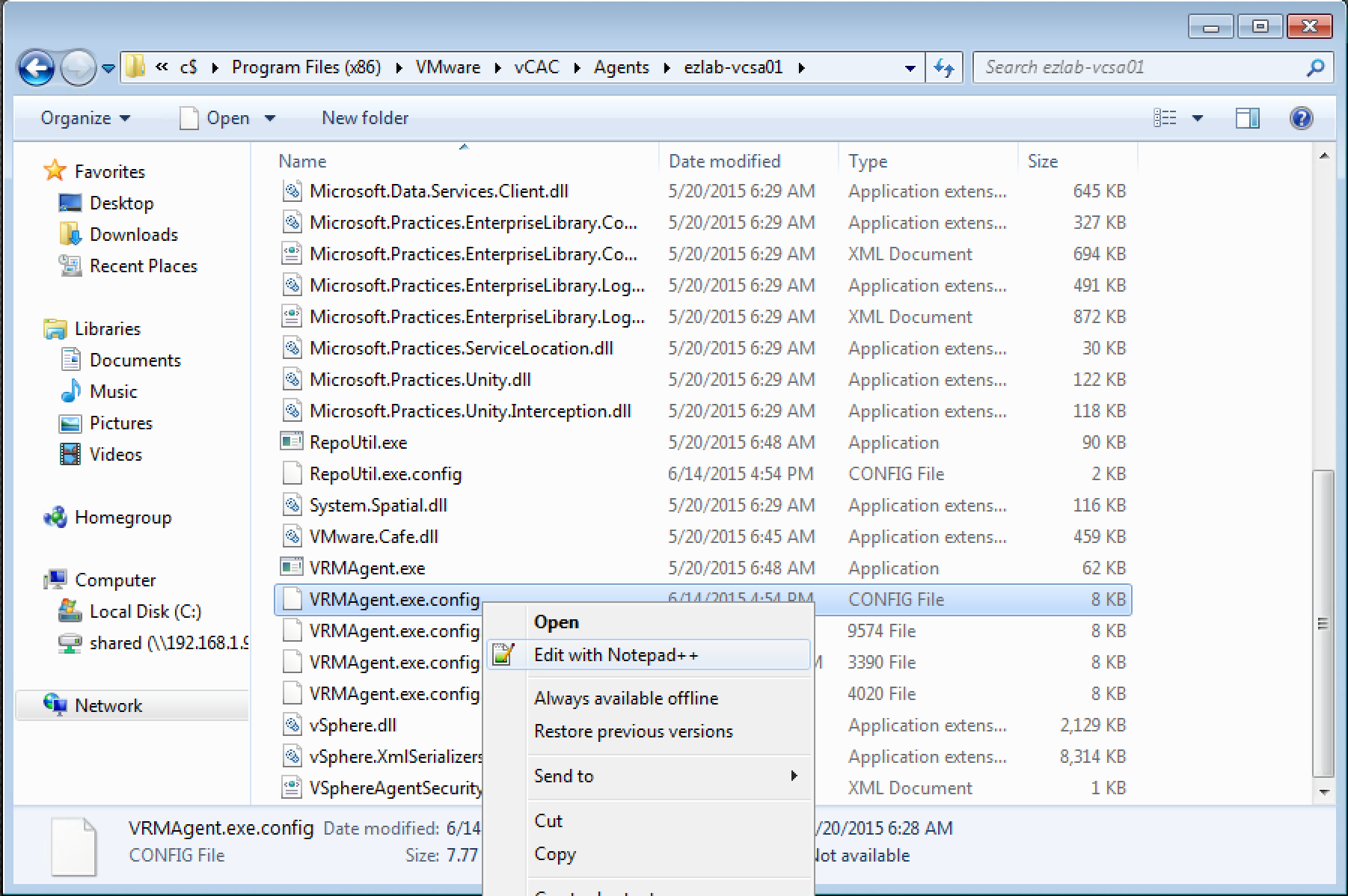
4. Locate the section called “serviceConfiguration” (line 78)
5. Find “activeQueueSize”, change the default value from 10 to the desired number
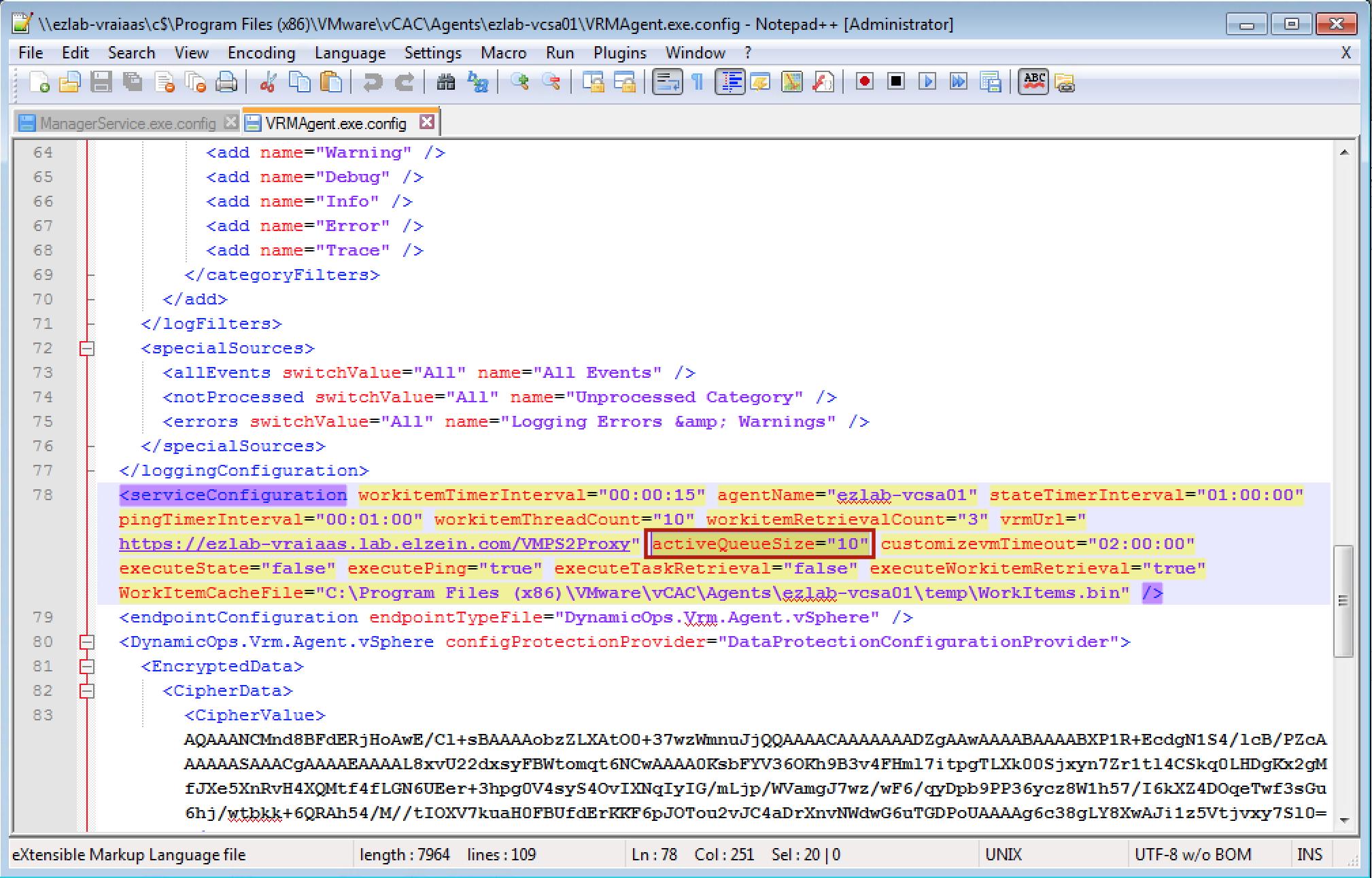
6. Save the changes and close the file
7. Restart the appropriate agent service
8. Repeat on any HA pairs
You’re going to want to test everything in a Test/Dev environment before rolling these changes out to Production. By the way, the settings above are documented and supported by VMware…just do yourself a favor and BACK EVERYTHING UP before changing anything as there is plenty of opportunity to change/edit/delete the wrong bits along the way.
Enjoy!
+++++
@virtualjad
Hi Jad,
thanks for this great post!
But I a have a question about the option “MaxOutstandingResourceIntensiveWorkItems”:
Does 2 of them only mean e.g. the CloneProcess in vCenter or the whole process (vCO Stub – Template Clone – vCO Stub) until its finished?
Kind Regards,
Markus